What is the local query cloud?
In short: This feature allows to combine data from multiple Caché Servers, Caché Namespaces but also other database vendors are supported. Combine tables from Microsoft Access, Microsoft SQL Server or other database vendors or from simple CSV Files by writing a simple sql query.
All this without any installation on Server Side!
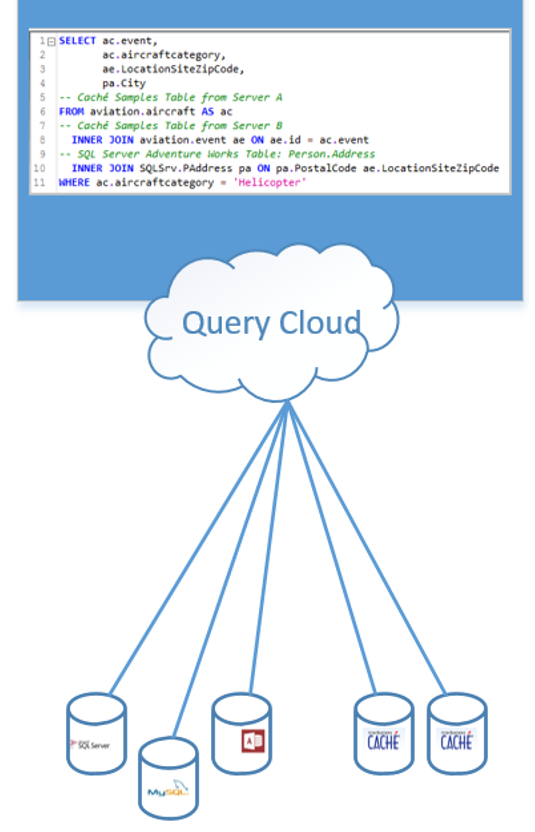
Use the Local query Cloud to access data across servers, namespaces and other connections in ONE sql statement. The Local Query Cloud is like a local virtual database. Within this virtual database you can query and use data from different places, combine with e.g. SQL like joins as if they are in the same Caché Namespace or the same database. You don’t need to move any data into the same place to make some queries.
No data is transported to any public cloud system! All queries and data is localy processed from SQL Data Lens.
All this is done with zero installation on the Server side. Please watch this video to see how it works. This video demonstrates how you can work with CSV files within the Query Cloud and query the data like database tables.
Add table virtualy to the query cloud
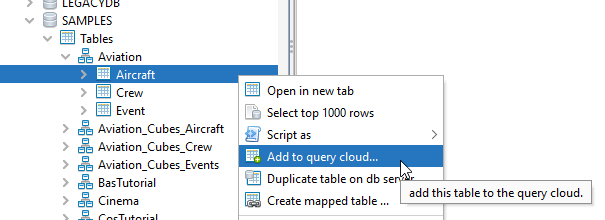
To work with the Local query cloud you have to add your tables first to that virtual database. Go to all your source tables you want to combine and select “Add table to query cloud…”.
No data will be copied! The query cloud only save information about the source of that tables:
What options we have to query data from different places without to move the data and what are the differences between all of them?
Linked Server
Several database products, such Microsoft Access, Microsoft SQL Server, Sybase and more have the ability to “link” a table into the current server instance. With that you can write queries as if that table was actually stored on the particular server. This is a very useful feature that will often allow you to avoid loading data into another source while still being able to execute a query.
Caché\IRIS SQL Gateway
The Caché SQL Gateway provides access from Caché to external databases via JDBC\ODBC. So this is a similar technique like the Linked Servers in Microsoft SQL Server.
To linking to a Table\View from a external source you have to create a Gateway Connection. After that you have to use a wizard from Caché Management Portal to link to an external table in an ODBC- or JDBC-compliant database. Link means here that there is a class created that redirect all calls to the external table. Now you can query this table within Caché.
The drawback of that feature: The user need to be autorized to use the SQL Gateway, create connections, create tables and more. All the tables listed in the FROM clause of an SQL query must come from the same data source. Queries that join data from heterogeneous data sources are not allowed.
Caché monitor mapped-tables for intersystems caché
Caché Monitor Mapped-Tables feature is something like the Caché SQL Gateway and the Caché Link Table Wizard in one. This features is limited to InterSystems Caché and allows to map\link the data storage of a class\table into another namespace. With that you can combine and query the data in a sql statement as if that table was actually stored in same namespace like the other tables.
The drawback of that feature: Mapped-Tables only works for Caché and need be configure on server side. The User need to be very carefully while execute delete operations on Mapped-Tables! Cause the original table and the Mapped-Table(s) are use the same data storage.
What these techniques have in common?
All the work is done on Serverside by the database server. The query optimizer can choose the right plan to get the data as fast as possible and only the result of the query is send back to the client (SQL Data Lens). So the client has nothing to do just show the result. This is quit good from performance perspective.
BUT if you only want to do some adhoc queries across multible databases for analysis purposes you have to do a lot of configuration first.
With the Query Cloud the user can combine data from all sources they have access to. Only a working connection from SQL Data Lens is required. The User don’t need any special rights to that neither any configuration on server side.
This techniques has also a drawback:
All the work is done on client side. So the client need more ressources (memory\cpu) to do the job. So mayby this is not the right way to work with very large tables with millions of rows. But it is fantastic feature to make some fast ad hoc analysis on the data without moving them.